by Gihan Samarasinghe
We are living in the age of digitisation. Each day hundreds of Terabytes of data are being dumped into digital storage networks (World Wide Web is the largest of them all). Unfortunately, most of them are unstructured and randomly ordered. Think how much of unordered, unstructured information can be shared on Twitter and Facebook within few seconds!
Discovery of the potentially important information hidden among unstructured data stored on the internet has always been an active research topic. That is where Natural Language Processing (NLP) comes to aid. NLP is one of the strongest branches of Artificial Intelligence (AI), where recordings/articles containing spoken or written human languages are analysed by computer algorithms to extract and represent useful information in a structured manner.
Role of Text Mining
There are many data mining and machine learning techniques available for the purpose of knowledge discovery in natural language contexts, and the term text mining is generally used for the techniques used to analyse text-based data sources. What basically happens in text mining is the statistical prediction of the relevance of a text-based data instance with respect to a particular subject of interest, either based on prior learned inter-relations of sets of keywords or predicted correlations among newly seen word groups. Those predictions are usually represented as lexical, syntactical and semantical analyses of text contents.
Can Text Mining Benefit from Deep learning?
The idea and evolving implementations of the family of machine learning techniques called Artificial Neural Networks (ANN) existed since the 1940s. ANN algorithms imitate and are influenced by the neural networks of animal brains. Traditional classification techniques in machine learning need a set of pre-defined features to learn from a presented instance (the process called Training). ANNs, on the other hand, contains several sequential middle layers (called hidden layers because the feature definitions are unexplained and fuzzy in these layers), that defines the features by themselves by observing the important aspects of training instances.
The rate of learning depends on two factors mainly: (i) the number of hidden layers and (ii) number of training instances. Until the early 2000s, the vital bottleneck was the unavailability and the higher cost of computational power and storage. When these issues were addressed with revolutionary hardware inventions such as fast computations using Graphical Processing Units (GPUs), faster digital read and write on Solid State Drives (SSDs), etc, ANNs also gained a rapid enhancement. This was the beginning of the popular term Deep Neural Networks, that is nothing more than ANNs with a larger number of layers (deeper) and hence a better learning rate. Day by day, various fields have benefitted from deep neural networks with the availability of millions of data and vast computational power. Meanwhile, Deep Neural Networks themselves are evolving with optimised algorithms and frameworks, therefore becoming more and closer to the way how human brain thinks and understands things (although machine learning is still far behind our brain). The following figure gives a nice overview of how Deep Learning becomes better when there is more data to train with, and capability to handle more data.
We are living in the age of digitisation. Each day hundreds of Terabytes of data are being dumped into digital storage networks (World Wide Web is the largest of them all). Unfortunately, most of them are unstructured and randomly ordered. Think how much of unordered, unstructured information can be shared on Twitter and Facebook within few seconds!
Discovery of the potentially important information hidden among unstructured data stored on the internet has always been an active research topic. That is where Natural Language Processing (NLP) comes to aid. NLP is one of the strongest branches of Artificial Intelligence (AI), where recordings/articles containing spoken or written human languages are analysed by computer algorithms to extract and represent useful information in a structured manner.
Role of Text Mining
There are many data mining and machine learning techniques available for the purpose of knowledge discovery in natural language contexts, and the term text mining is generally used for the techniques used to analyse text-based data sources. What basically happens in text mining is the statistical prediction of the relevance of a text-based data instance with respect to a particular subject of interest, either based on prior learned inter-relations of sets of keywords or predicted correlations among newly seen word groups. Those predictions are usually represented as lexical, syntactical and semantical analyses of text contents.
Can Text Mining Benefit from Deep learning?
The idea and evolving implementations of the family of machine learning techniques called Artificial Neural Networks (ANN) existed since the 1940s. ANN algorithms imitate and are influenced by the neural networks of animal brains. Traditional classification techniques in machine learning need a set of pre-defined features to learn from a presented instance (the process called Training). ANNs, on the other hand, contains several sequential middle layers (called hidden layers because the feature definitions are unexplained and fuzzy in these layers), that defines the features by themselves by observing the important aspects of training instances.
The rate of learning depends on two factors mainly: (i) the number of hidden layers and (ii) number of training instances. Until the early 2000s, the vital bottleneck was the unavailability and the higher cost of computational power and storage. When these issues were addressed with revolutionary hardware inventions such as fast computations using Graphical Processing Units (GPUs), faster digital read and write on Solid State Drives (SSDs), etc, ANNs also gained a rapid enhancement. This was the beginning of the popular term Deep Neural Networks, that is nothing more than ANNs with a larger number of layers (deeper) and hence a better learning rate. Day by day, various fields have benefitted from deep neural networks with the availability of millions of data and vast computational power. Meanwhile, Deep Neural Networks themselves are evolving with optimised algorithms and frameworks, therefore becoming more and closer to the way how human brain thinks and understands things (although machine learning is still far behind our brain). The following figure gives a nice overview of how Deep Learning becomes better when there is more data to train with, and capability to handle more data.
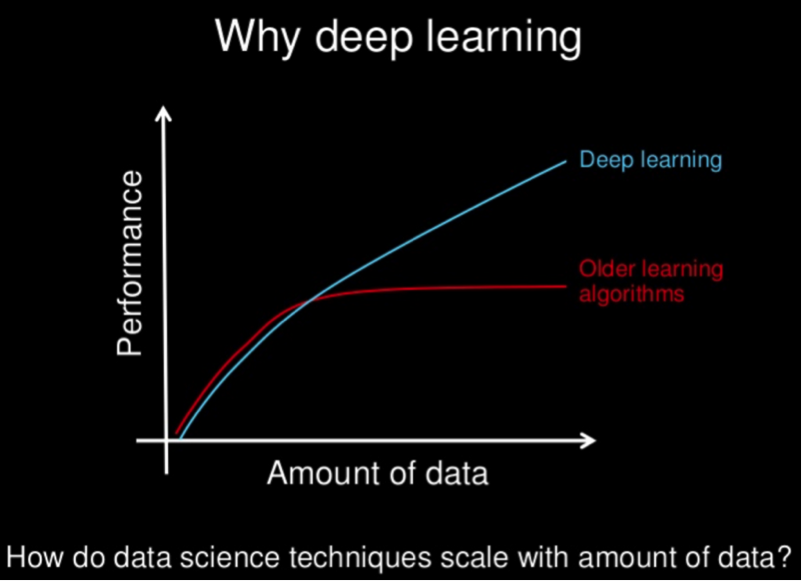
Text mining couples with deep neural networks brilliantly, due to the nature of the understanding needed in text context classification and knowledge discovery. Deep learning-based text mining techniques have become quite popular and successful in self-discovery and interpretation of interesting features (keywords) and have already shown promising signs of becoming superior to traditional machine learning techniques.
Future of Systematic Mapping
Systematic mapping of evidence for a topic of interest, in literature, is an imperative potential usage of text mining, when large networks of millions and billions of text articles are available, and yet to be summarised or collected meaningfully. In this process, defining a proper set of keywords or search terms is a tricky task, and they are heavily subjective and ambiguous. Therefore, deep neural networks are the way to go with future knowledge hubs and structured literature collections. Not only better classification of text documents using a self-defined set of keywords (with a proper training process), but also visualising and presentation of the learned interpretations will be potentially interesting outcomes of deep learning based literature surveys.
Further Reading
- Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K. and Kuksa, P., 2011. Natural language processing (almost) from scratch. Journal of Machine Learning Research, 12(Aug), pp.2493-2537.
- Moens MF. Argumentation mining: How can a machine acquire common sense and world knowledge?. Argument & Computation. 2017 Jan 1(Preprint):1-4.
- Hirschberg, J. and Manning, C.D., 2015. Advances in natural language processing. Science, 349(6245), pp.261-266.
- Jason Brownlee, August 16, 2016. What is Deep Learning. machinelearningmastery.com
- Andrew Ng. Deep Learning, Self-Taught Learning and Unsupervised Feature Learning. YouTube Video
 RSS Feed
RSS Feed